Op 20 februari 2020 hielden wij de tweede bijeenkomst van de begeleidingsgroep voor de voorbereidende TETRA AI. We vatten nog even de meest essentiële zaken van deze bijeenkomst samen in deze blogpost.
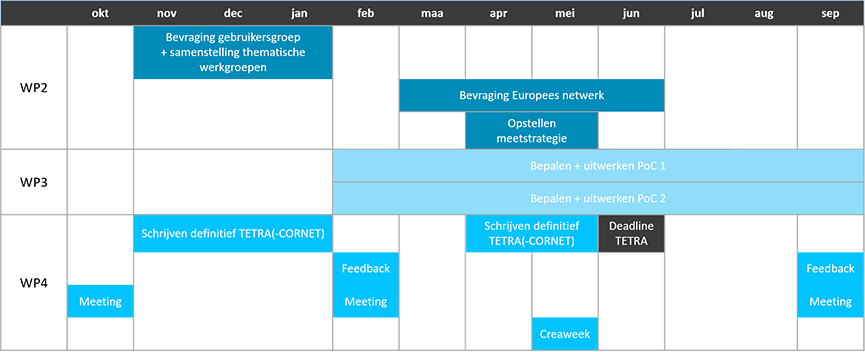
Updated Timeline
Sinds de vorige bijeenkomst is er een nieuwe TETRA call aangekondigd specifiek voor AI-projecten. De deadline voor deze nieuwe call ligt op 2 juni. We hebben ervoor gekozen om ons dossier op deze nieuwe call in te dienen. Dit om 2 redenen. Deze nieuwe datum staat ons toe om nog meer van jullie input te verwerken in het uiteindelijke dossier, en dus de planning van de komende twee jaar. Daarnaast is de kans groot dat ons project toch doorgestuurd zou worden naar de AI-specifieke call.
Bevraging & Resulaten
We zijn de bevraging begonnen met individuele interviews. Via deze weg wouden we enerzijds polsen naar de interesse in de verschillende onderwerpen die we zelf al op het oog hadden, en anderzijds wouden we de verdere onderwerpen die jullie nog in gedachten hadden verzamelen. Het was inderdaad zo dat doorheen de bevragingen nog nieuwe onderwerpen bovenkwamen. We vonden het belangrijk iedereen de kans te geven om ook voor deze onderwerpen hun interesse te tonen, waarop we de online Survey uitstuurden samen met een beknopte uitleg van de mogelijke onderwerpen. Die uitleg kan u hiernog steeds terugvinden.
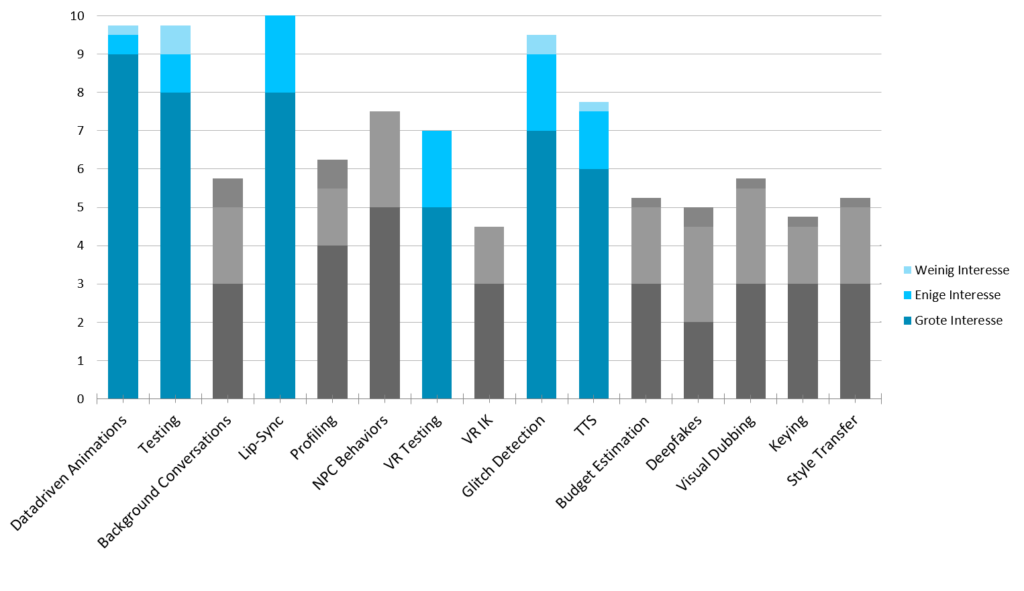
De resultaten van de bevraging kan u terugvinden in bovenstaande grafiek. We hebben in deze ronde 14 bedrijven bevraagd. Elk bedrijf kon aanduiden of ze "grote interesse", "enige interesse", "Weinig interesse" of "geen interesse" had in een bepaald onderwerp. Respectievelijk telde hun stem zo mee voor een hele, een halve, een kwart of geen stem in de uiteindelijke telling. We overlopen hieronder wat we kunnen opmaken uit deze resultaten.
We onderscheiden 4 major topics waarop de focus van de volledige TETRA zal liggen.
Het eerste onderwerp waar duidelijk veel interesse in is, is datagedreven animaties. Het is duidelijk dat zulke systemen een grote tijdswinst zouden kunnen opleveren, maar binnen de grebruikersgroep vraagt men zich af hoe het zit met het verlies van controle over het eindresultaat.
Een tweede onderwerp waar we veel interesse in zien, is geautomatiseerd testen. Er is ook specifiek veel interesse in het automatisch testen van VR-games. Velen onder de gebruikersgroep vragen zich af hoe direct toepasbaar en nuttig automated testing kan zijn, maar zien er wel veel potentieel in.
Hiernaast zien we ook grote interesse in lip-sync en tekst-to-speech; deze twee technieken zijn nauw verwant met elkaar, en beiden tonen veel potentieel, maar missen nu nog een bepaald niveau van kwaliteit. We zien hier ook potentieel voor een inkoppeling van de foneem-herkenning die al intern ontwikkeld wordt.
Een vierde topic waar veel interesse in is, is glitch detection. Hiermee bedoelen we het gebruiken van AI om visuele anomalieën automatisch te detecteren. Denk daarbij bijvoorbeeld aan missende objecten in een scene of textures die niet correct geladen worden. Ook render-issues zoals aliasing , wat zeker in VR nog een groot probleem vormt, vallen hieronder. Hoe effectief en universeel implementeerbaar dit zou zijn, was een veelgestelde vraag.
Proof of Concepts voorbereidingsjaar
Om al een aanzet te geven naar het vervolgtraject, voorzien we binnen dit voorbereidingsjaar nog ruimte om enkele Proof of Concepts (PoCs) uit te werken. Deze PoCs zullen sterk aanleunen bij de specifieke use cases die we in de volledige TETRA. De twee PoCs waar we voor gekozen hebben zijn automatisch testen en datagedreven animaties. We lichten deze even in iets meer detail toe.
De PoC rond automatisch testen bestaat uit 2 delen. Deel 1 omvat het onderzoeken van automatische test-sequenties
In de PoC rond datagedreven animaties zullen we de volledige workflow van datagedreven animaties start to finish doorlopen, om zo een goed beeld te vormen van exact hoeveel tijd er mee bespaart zou kunnen worden, en exact welke voor- en nadelen deze techniek verder nog heeft.
Uit de bevragingen bleken volgende zaken de belangrijkste knelpunten te zijn met deze technologie; het styleren van animaties, de responsiveness, en het toevoegen van meer dynamische animaties. Binnen deze Proof of Concept zouden we een eerste aanzet willen doen om deze problemen te onderzoeken. Deze proof of concept lijdt dan direct naar de volledige TETRA, waar we een Use Case zullen hebben die verder gaat op dit onderwerp.
PoC automatisch testen
De PoC rond automatisch testen bestaat uit 2 delen. Deel 1 omvat het onderzoeken van automatische test-sequenties in games, en hoe deze robuuster kunnen gemaakt worden. Deel 2 omvat een onderzoek naar bestaand Computer Vision modellen en hun bruikbaarheid op visuals uit de game-, vfx- of animatie-pipeline om visuale anomalieën te herkennen. Hieronder een beknopte uitleg.
Niet alleen in het testen van games, maar ook in het testen van software in het algemeen wordt vaak gewerkt met bepaalde stappenplannen of sequenties die voltooid dienen te worden. Wanneer Een sequentie niet kan voltooid worden is er typisch sprake van een fout in de software. Om deze sequenties te automatiseren zouden we gebruik kunnen maken van bots die leren hoe ze stap voor stap doorheen een sequentie kunnen lopen door het game te spelen. Deze bots zijn robuuster tegen kleine veranderingen in de applicatie. We bekijken 2 mogelijke invalshoeken: bots getrained met Reinforcement Learning, en een klassieke implementatie van Monte Carlo Tree Search.
Visuele bugs in games zijn vaak in 1 oogopslag merkbaar. Indien een eerste controle door een automatisch AI model gebeurt kunnen fouten sneller gedetecteerd worden. Het grote voordeel van Computer Vision is dat er op dit moment al een rist aan bestaande architecturen bestaan die wel degelijk werken. Wat deze PoC dus moet aantonen is dat deze modellen toe te passen zijn op een eigen dataset met door de gebruiker gespecifieerde kenmerken die gedetecteerd dienen te worden. We willen onderzoeken welke modellen het beste passen, op welke manier best data wordt verzameld en (automatisch) geannoteerd, en hoe deze te integreren zijn in een pipeline.
PoC datagedreven animaties
In de PoC rond datagedreven animaties zullen we de volledige workflow van datagedreven animaties start to finish doorlopen, om zo een goed beeld te vormen van exact hoeveel tijd er mee bespaart zou kunnen worden, en exact welke voor- en nadelen deze techniek verder nog heeft.
Uit de bevragingen bleken volgende zaken de belangrijkste knelpunten te zijn met deze technologie; het styleren van animaties, de responsiveness, en het toevoegen van meer dynamische animaties. Binnen deze Proof of Concept zouden we een eerste aanzet willen doen om deze problemen te onderzoeken. Deze proof of concept lijdt dan direct naar de volledige TETRA, waar we een Use Case zullen hebben die verder gaat op dit onderwerp.
Stageproject
We verwelkomen ook een nieuw lid in het AI team; Zeno Watteeuw zal bij ons stage doen tot juni, en zal binnen zijn stage het onderzoek rond geautomatiseerd VR-testen in gang zetten.
Specifiek zal hij werken rond game- en speleranalyse door middel van bewegingsimulaties in VR. Dit wordt ontwikkeld in het kader van een VR sandbox die typische VR mechanics bevat. Een virtuele controller kan hier dan bewegingen en acties simuleren om zo de mechanics te testen. Als we dan kijken hoe we bewegingen kunne classificeren volgens bepaalde kenmerken, kunnen verschillende speelstijlen geprofileerd worden. Afhankelijk van hoe vlot dit loopt, volgt daarop dan bewegingsanalyse met als doel de content van de game dynamisch af te stemmen op het profiel dat gedetecteerd wordt voor de speler.
En verder?
Summer School
Verder gaan we dit jaar in juni met het AI team naar de AI & Games Summerschool van modl.ai in Kopenhagen. Dit evenement wordt meegeorganiseerd door o.a. Unity, Deepmind en Microsoft. Het onderwerp van deze summerschool overlapt volledig met ons project, en we zullen de summerschool kunnen gebruiken om af te toetsen of er internationaal rond dezelfde onderwerpen gewerkt wordt.
Survey
Tijdens het schrijven van het dossier is het ons duidelijk geworden dat we nog bepaalde specifieke data missen die het TETRA dossier kunnen versterken. Specifiek hebben we het dan over zaken zoals hypothetische tijdswinst en kostenbesparing. Via een online survey zullen we polsen naar deze zaken.
Verder volgt er uiteraard ook nog de internationale bevraging, in de survey zullen we jullie ook de kans geven om specifieke internationale bedrijven aan of af te raden.
Een link naar de survey vindt u alvast hier terug: [survey]
Workshops
Dit jaar willen we ook nog 2 workshops inplannen voor de gebruikersgroep. Voor de eerste workshop stellen we voor een algemene workshop rond AI te doen, dit met het doel om jullie een goed beeld te geven van hoe AI werkt, welke soorten AI er bestaan, en waar ze voor gebruikt kunnen worden. Dit zal dus vooral een informerende workshop zijn. De tweede workshop zou een hands-on sessie zijn waar we aan de slag gaan met Reinforcement Learning.
Voor de specifieke datums voor deze workshops kan u onderstaande doodle invullen, het is zeker toegestaan om iemand anders uit uw bedrijf, die er mogelijks meer aan heeft, naar deze workshops te sturen.
Een link naar de doodle vindt u alvast hier terug: [doodle]
Verder verloop
De eindmeeting van dit voorbereidingsjaar staat natuurlijk wel al vast, deze zal plaats vinden op 10 september.
De deadline voor het indienen van het TETRA dossier voor het vervolgtraject staat vast op 2 juni. De jury zal dan rond oktober samenzitten, en als alles goed gaat, zou het vervolgtraject dan in het begin van 2021 van start kunnen gaan.