Automatisch code genereren met taalmodellen
Goed nieuws voor mensen zonder programmeer ervaring. Je kan nu een spelletje in elkaar flanzen zonder zelfs een letter code te typen. We kunnen nu weldegelijk automatisch code genereren met taalmodellen. Dit gebeurt aan de hand van eenvoudige opdrachten, of het model vult bestaande code gewoon aan. En voor beginners: een taalmodel kan jouw code nakijken op syntax fouten en deze ook nog eens automatisch optimalizeren.
Ook voor meer ervaren programmeurs is er soms nog sprake van repetitie of opzoekwerk. Zeker bij het jongleren tussen verschillende talen. In deze blogpost zien we hoe programmeren nu makkelijker wordt dan ooit tevoren.
Taalmodellen
Dus, hoe werkt dit precies? Net zoals we tussen Engels en Nederlands kunnen vertalen met AI, blijkt het ook mogelijk om Engels om te zetten naar code. Of van slechte code naar goede code! De naam van zo een AI die taalproblemen oplost is een taalmodel. We hebben het hier al voorbeelden van gezien in onze blogpost over conversational AI.
Het leuke hieraan is dat er heel wat interessante mogelijkheden zijn om deze te gaan gebruiken.
GPT-3
GPT-3 heeft misschien geen introductie nodig. Dit model staat bekend door zijn capaciteiten om zeer geloofwaardige tekst en artikelen te kunnen schrijven. Hieronder alvast een voorbeeld van mei 2020:


Je kan verder lezen onder: https://t.co/W1PVlsHdu4
Leuke achtergrondinformatie: GPT-3 heeft 45TB (zonder compressie) aan tekst geabsorbeerd van verschillende datasets. Deze enorme opgave heeft tussen de $4 miljoen en $12 miljoen gekost. Om dit in perspectief te zetten: Wikipedia in zijn geheel is minder dan 20GB groot, of 0.02TB. GPT-2, de voorganger, werd op 40GB aan tekst getraind. Deze laatste versie heeft dus informatie van over het hele internet verzwolgen. Hierdoor heeft GPT-3 ervaring over vanalles en nogwat. Hier is een voorbeeld waarbij moeilijke legale teksten worden omgezet naar simpel Engels:
With a few lines of Python and @sh_reya’s gpt-3 sandbox I got a demo web app up and running in less than 30 mins. What an incredible time to learn about software and be able to test things out so rapidly. pic.twitter.com/594ZUba885— Michael (@michaeltefula) July 26, 2020
Code genereren
Ok, we hebben het dus gehad over tekst genereren en moeilijke legale documenten omzetten naar eenvoudig Engels. GPT-3 is duidelijk een krachtig model, maar hoe presteert het taalmodel bij het genereren van code?
Ondertussen zijn er om code te genereren al verschillende variaties van GPT-3 beschikbaar onder verschillende namen. SourceAI, een betalende API die nog niet beschikbaar is; GitHub Copilot, waarbij u het product bent; en OpenAI Codex, waarbij u waarschijnlijk eeuwig op de wachtlijst zal blijven staan.
SourceAI
SourceAI toont in een eenvoudige demo alvast drie use cases: translate, simplify en debug:
Codex
Op de website van OpenAI vindt u een demo die toont hoe ze met Codex in enkele minuten een space game maken, louter aan de hand van de code die gegenereerd wordt:
OpenAI gaat nog een stap verder en toont met een uitgebreide live demo de verschillende mogelijkheden aan van Codex:
Open source
Spelletjes maken en automatisch code genereren met taalmodellen is heel cool, maar geen van voorgaande opties zijn voorlopig bruikbaar wanneer u met productie code aan de slag gaat. Elk van deze opties berust op GPT-3, welke niet openlijk toegankelijk is.
Het leuke nieuws is, ook zonder GPT-3 kunnen we gaan experimenteren.
EleutherAI
Ontmoet EleutherAI, een collectief van onderzoekers dat zich inzet om AI onderzoek open source te houden.
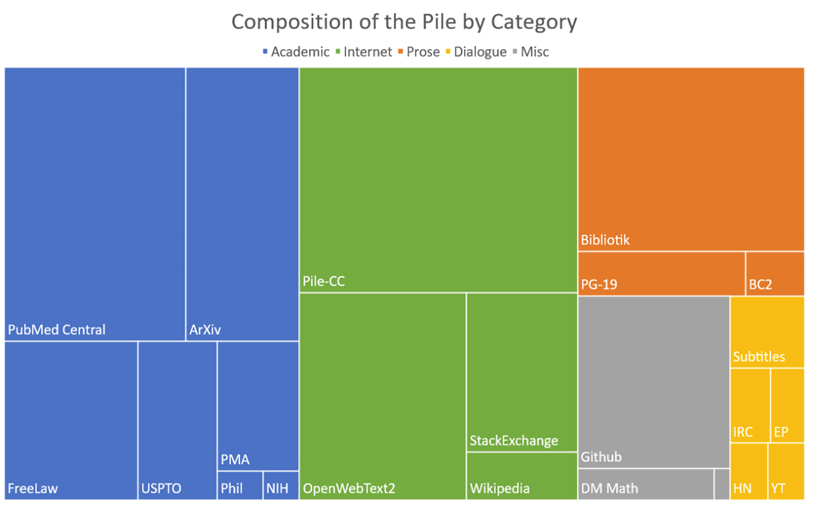
Eleuther stond aanvankelijk bekend om The Pile, een dataset van 825GB die op zijn beurt een collectie is van 22 andere datasets van hoge kwaliteit. De domeinen van deze dataset liggen uiteen, gaande van boeken, webpagina’s en chat logs tot medische teksten, fysica, wiskunde, computerwetenschappen en philosofie.
Inmiddels zijn ze zelf ook op de proppen gekomen met een taalmodel, gedoopt als GPT-J-6B, welke uiteraard op hun eigen dataset is getraind.
De bedoeling van GPT-J-6B, welke niet achter stoelen of banken wordt gestoken, is om de GPT modellen van OpenAI zo goed mogelijk na te bootsen. De pre-trained modellen vindt u op Hugging Face.
Hier alvast enkele voorbeelden van wat dit model kan. Deze heb ik telkens zelf verzonnen, voel u dus vrij om er nog verder mee te spelen. De vetgedrukte tekst is telkens de input voor het taalmodel, hier bouwt hij dan op verder en gokt hoe het vervolg er uit moet zien. U kunt zien dat de structuur telkens heel mooi wordt overgenomen en vervolgens wordt aangevuld.
Genereren van tekst
Hier ben ik begonnen met iets dat lijkt op de titel van een artikel. Het model heeft deze nog iets verder aangevuld en is toen begonnen met content te verzinnen die bij deze titel past. Let wel, dit betekent dat het model dingen duft te zeggen die grammaticaal correct zijn maar in werkelijkheid helemaal niet kloppen.

Legale tekst
Hier is het overgrote gedeelte input om het model de structuur te doen snappen van de gewenste uitkomst, en is de belangrijkste informatie dus de eerste paragraaf die hier op volgde. Hier na kwamen nog een aantal paragrafen, weggeknipt uit deze screenshot, en begon het model zelf nog voorbeelden te verzinnen van legale clausules die hij dan ook naar simpel engels omzette. Let hier dus op wanneer u de output zou willen parsen van een taalmodel.

Dialoog
Voor diegenen die met een writer’s blok zitten en een dialoog willen generen tussen virtuele characters, of een chatbot willen bouwen, ook dit blijkt mogelijk te zijn. De input is opnieuw compleet willekeurig door mij gekozen geweest, samen met de output die ik daarbij de eerste keer kreeg, zonder cherry-picking. Persoonlijk vond ik onderstaand gesprek echt indrukwekkend.
Code
En dan zijn we nu aangekomen bij het automatisch genereren van code. Diegenen die The Pile hierboven goed bestudeerd hebben zullen gemerkt hebben dat GitHub en StackExchange een mooi aandeel zijn van de de dataset.
Eens kijken of het model onderstaande klasse in C# kan aanvullen.

Ondanks dat dit uiteraard niet de juiste vervolg code is, is het al een goed teken om te zien dat de haakjes worden gesloten en een variabele wordt herbruikt. Ook wordt het idee gesnapt dat er mogelijke andere keypresses mogelijk zouden zijn.
Eens vergelijken met het SQL voorbeeld van SourceAI. In het volgende geval heb ik de temperatuur (creativiteit) van het model wat omlaag gehaald:
Het model heeft hier geen voorbeeld gekregen hoe dat de structuur er moet uit zien van het antwoord waardoor de uitdaging nog net iets ingewikkelder wordt. Opnieuw wordt er hier teveel tekst uitgespuugt. Uiteindelijk komt er wel een antwoord dat min of meer correct is, maar net zoals GPT-3 gaan de beide taalmodellen er hier spontaan van uit dat er een ID kolom is die op 1 moet staan.
Taalmodel lokaal gebruiken
Omdat het taalmodel dat ik dusver gebruikt heb gigantisch is en niet zo maar in twee kliks lokaal op uw systeem draait is deze ook beschikbaar gemaakt via uw browser. Op deze manier kan echt iedereen de capaciteiten van zo een model eens testen. Het volgende voorbeeld is niet meer via de webbrowser maar een versie die lokaal draait.
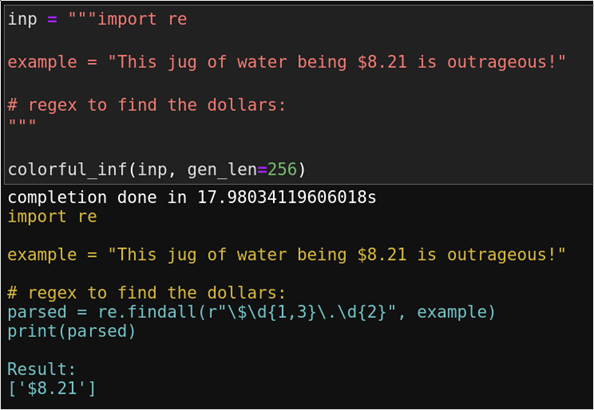
Het resultaat hierboven is prachtig. De gele tekst is input, en de blauwe tekst is de output code die is gegenereerd door het taalmodel. Niet alleen wordt hier de juiste code gegenereerd, er wordt ook nog een print statement toegevoegd mét de verwachte output van de gegenereerde code. Dit allemaal zonder compiler, uiteraard.
GPyT
Op Hugging Face is er een model genaamd GPyT te vinden. Dit is een versie van GPT-2 die vanaf nul op 80GB aan python code is getrained geweest. Uiteraard gaat deze versie niet opwegen tegen Codex, maar op ste minst kan je dit model volledig bestuderen en eens testen tot zijn limiten. De auteur waarschuwt hier wel tegen het gebruik in productie, aangezien het model zo maar eens nefaste of gecopyrighte code zou kunnen uitspuwen.
Conclusie
Het ziet er naar uit dat taalmodellen die automatisch code genereren op termijn een onderdeel kunnen worden van het dagelijkse leven voor sommige programmeurs. Op dit moment is het echter nog een gimmic om te gebruiken voor onderzoek of bij persoonlijke projecten. In welke mate dat de hype aanslaat en succesvol is, valt nog af te wachten.
Aangezien GPT-4 mogelijk tot 500x groter zal zijn dan GPT-3 is de kans reeël dat er in de nabije toekomst grote sprongen op vlak van programmeer-assistentie zullen worden gemaakt. Ook EleutherAI staat niet stil en is druk bezig om een open source en waardig alternatief voor GPT-3 uit te brengen. Deze modellen zullen ongetwijfeld meer en meer use cases krijgen voor het gebruik in ons dagelijks leven.