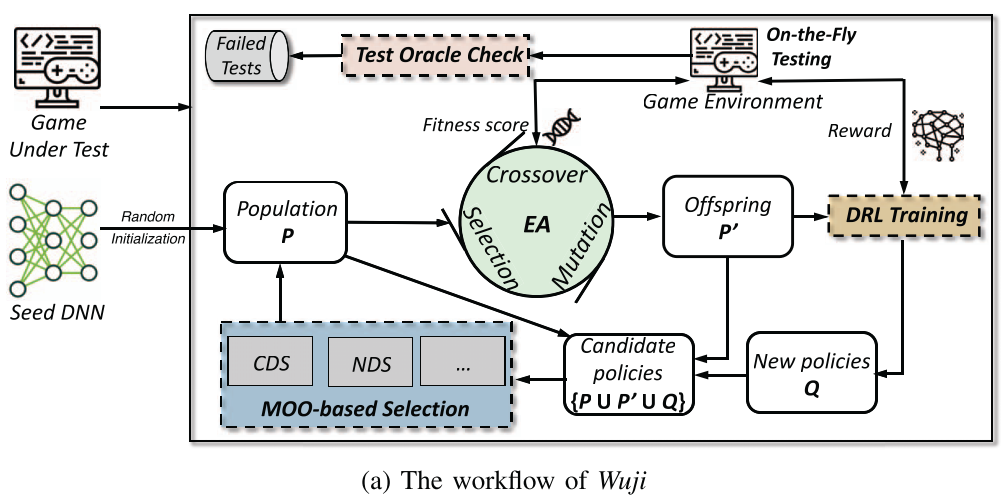
De RL-lus indachtig definiëren we hier de observatie, output en reward signal van de agents. Belangrijk is dat de bots net zoals echte spelers in interactie gaan met de applicatie. Daarom maken ze geen gebruik van een navigatie graaf of navmesh. Een Deep Neural Network vertaald de observatie naar een juiste actie.
De observatie is opgebouwd uit verschillende orientatie features (positie, velocity, rotatie), player states (is climbing, on ground, jump cool-down time) en een zichtsveld (12 raycasts die een afstand tot collision weergeven en een semantische mening over het oppervlak). De auteurs bespreken ook een variant waarbij een additioneel first-person view meegegeven wordt.
Mogelijke acties komen overeen met input acties die de speler kan nemen. Zo zijn er 3 continue acties (vooruit/achteruit, draai links/draai rechts en stap links/stap rechts) en 1 discrete actie (jump).
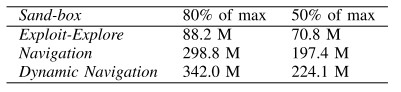
De reward signal bepaalt het gedrag van de agent. Het gewenste gedrag in dit geval is een agent die de map gaat exploreren. Het maakt dus niet uit goed de agent het spel speelt maar wel op hoeveel plekken in de map de agent zich begeeft. Om dit te bereiken krijgt de agent een beloning wanneer hij op onontdekt terrein komt.
Het gekozen trainingsalgoritme is Proximal Policy Optimization (PPO). Een populair algoritme door de robuustheid en ook geïmplementeerd in Unity ml-agents.