Audio in games
Audio is essentieel voor het succes van elk spel. Het zorgt voor een meeslepende ervaring die het verschil kan uitmaken tussen een speler die van je spel geniet of gefrustreerd raakt en opgeeft.
Met deze use case willen we gaan onderzoeken wat de impact kan zijn van AI voor audio in games en of we aan mogelijke problemen een mouw kunnen passen, zoals bijvoorbeeld het detecteren van fouten in de muziek of geluidseffecten van games.
Vertraagde, ontbrekende of verkeerde geluidseffecten kunnen namelijk de immersie van het spel grondig aantasten. Aan de andere kant kan er ook inconsistentie of verandering van volume zijn van de achtergrondmuziek.
Dit kan spelers al dan niet storen tijdens het spelen, maar de juiste geluidseffecten of achtergrondmuziek bepalen nu eenmaal de sfeer tijdens het spelen van een spel. Bovendien is audio een belangrijk element om te bepalen wat er op elk moment in het spel gebeurt. Het kan juist op zo een vervelend moment zijn dat jouw vijanden je van opzij besluipen, waardoor ze het voordeel hebben om aan te vallen.
Helaas komen problemen met audio effectief nog steeds voor in games. Ze kunnen worden veroorzaakt door een aantal factoren, waaronder codewijzigingen, assets die niet goed zijn geoptimaliseerd, of gewoon de manier waarop het spel wordt gespeeld. We refereren hiernaar als bugs.
Audiobugs actief gaan opsporen vereist best wat tijd. Bovendien worden deze soms over het hoofd gezien omdat game testers een lagere prioriteit geven aan audio. Zo durft men wel eens zonder hun koptelefoon of met de volumeknop op 0 gaan testen, omdat grafische en functionele bugs opsporen gepaard gaat met veel herhaling, waarbij dus ook geluidseffecten telkens ad nauseum worden afgespeeld.
In deze use case onderzoeken we manieren om audiobugs automatisch op te sporen tijdens de ontwikkeling. Dit kan u helpen ze te identificeren en op te lossen voordat ze de spelers problemen bezorgen. We laten echter de meer genuanceerde uitdagingen met audio links liggen, aangezien het detecteren van technische zaken zoals de kamertemperatuur te niche zijn om verder in op te gaan.
Audiobugs
Soorten problemen met audio in games
Hieronder een korte opsomming van het soort problemen dat men kan tegenkomen met audio tijdens de ontwikkelfase van games.
Overrun voices
Wanneer verschillende stemmen tegelijk afspelen kan dit zeer storend zijn en de speler overrompelen. Idealiter heeft één karakter tegelijkertijd het woord, en spreekt hij niet over zichzelf heen met verschillende voice overs (VO) die over elkaar heen worden afgespeeld.
Reverberation
Reverb, in het Nederlands galm, is een geluidverschijnsel dat ontstaat bij herhaaldelijke weerkaatsing van geluid. Het is ook mogelijk om dit digitaal als een effect toe te voegen aan de audio waardoor het spelen met deze waarde het dus kan doen lijken alsof je in verschillende ruimtes zit. Wanneer de galm van geluidseffecten niet juist is afgestemd op de omgeving van het spel gaat de immersie enorm worden aangetast. Wanneer je in een spel in een klein hutje een zwaard smeedt maar de geluidseffecten klinken alsof je in een grote zaal op een gong slaat, dan werpt dat onmiddellijk wat vraagtekens op.
Occlusie
Verschillende ondergronden maken elk hun eigen specifiek geluid wanneer men er over wandelt. Denk maar aan de klank van jouw voetstappen op een ijzeren trap, een betonnen vloer of op een hard parket. In een game kan het soms voorkomen dat een bepaalde ondergrond of vlakte geen geluid maakt terwijl je dit wel zou verwachten, dit heet occlusie.
Niet gespatialiseerde effecten
Wanneer je een vogeltje in-game hoort fluiten, dan is de klankbron gespatialiseerd om deze vanaf een bepaalde richting te laten komen. Stel dat je hetzelfde vogeltje in beide oren keihard hoort fluiten maar hij zit 100 meter verder in een boom, dan heb je een probleem met een niet-gespatialiseerd effect.
Engine specifieke bugs
Dit is een vrij algemene categorie, maar zorgt niettemin ook voor problemen met audio. Een voorbeeld van een engine bug kan zijn dat geluidseffecten niet kunnen worden ingeladen, met een vertraging worden afgespeeld, of dat de audio hapert bij het afspelen.
Voice overs
Dit komt minder voor in productie, maar tijdens development kunnen de transcripten van de VOs wijzigen, kan de stem van het foute geslacht zijn, of worden de VOs per ongelijk omgewisseld of hergebruikt. Dit oplossen vereist dus het opnieuw en opnieuw blijven beluisteren of spelen het spel op het einde van elke iteratie of wanneer er significante wijzigingen worden doorgevoerd.
Doel van onderzoek
Er zijn talrijke type audiobugs die zich kunnen voordoen in games. Problemen met volume is iets dat men in principe kan automatiseren zonder het gebruik van AI. Om meerwaarde te halen uit een AI-oplossing die relevant is voor een breed publiek lijkt de juiste focus dus om geluidseffecten te gaan opsporen, al dan niet met overlappende achtergrondmuziek.
Het doel van ons onderzoek is bijgevolg om te onderzoeken in welke mate het mogelijk is om geluidseffecten te gaan detecteren. Vervolgens willen we ook de gedetecteerde audiofragmenten met exacte timestamps gaan bijhouden om zo een visueel overzicht te gaan genereren van de audio die in-game plaats heeft gevonden. Deze aanpak leent zich naast bugdetectie ook voor andere zaken, zoals het samenvatten van de highlights van een opname, of deze gaan voorzien van automatische tags op basis van de audio die is herkend in de video.
Met deze aanpak kunnen we bijgevolg drie types audiobugs gaan detecteren: ontbrekende, vertraagde en verkeerde audio.
Aanpak
We hebben de volgende fases uitgestippeld:
– Het aanleggen van een kleine dataset die represtatief is voor de geluidseffecten die in games kunnen voorkomen.
– Het trainen van een AI met deze dataset.
– Het testen van de AI en het meten van de performantie op alternatieve gelijkaardige geluidseffecten binnen dezelfde categorie.
Aanleggen van een dataset
In de eerste instantie hebben we een kleine dataset aangelegd met verschillende audio-effecten over een vijftiental categorieën verspreid. Dit varieert van het geluid van het zwaard tot UI clicks, we hebben glas dat breekt, piept of wordt gekrast, tot het openen en sluiten van sci-fi deuren met talloze variaties van bieps, zaps, en code unlocks die de deuren opent. Ook Foley zit in deze dataset, dit is een verzamelnaam voor allerdaagse geluiden die nodig zijn om de atmosfeer en games of film te gaan perfectioneren. Elke categorie varieert van 40 tot meer dan 100 samples aan geluidsfragmenten. Hieronder ziet u een overzicht van enkele geluiden uit de dataset met hun golfvorm. [DR1]
Op zich zeggen deze golfvormen niet veel, naast hun amplitude (y-as) over tijd (x-as). Het is informatiever om de informatie te gaan weergeven in de vorm van een mel-spectogram. Bij een mel-spectogram wordt de amplitude die voorheen nog op de verticale-as stond, nu weergegeven in de kleurdimensie in decibels. De verticale as toont nu het aantal Hertz, waarbij lage tonen onderaan het spectrogram worden weergegeven en de hogere tonen bovenaan.[DR2]
Onze audiobestanden hebben we dus geconverteerd naar afbeeldingen. Het overzicht van onze dataset ziet er nu als volgt uit:[DR3]
Enkele opmerkingen over de dataset. U kunt zien dat er min of meer een verband is tussen geluidseffecten uit dezelfde categorie. Dit voorbeeld is slechts een kleine steekproef van de honderden audiofiles in de dataset. Sommige geluiden uit dezelfde categorie lopen sterk uiteen, zoals het zwaard waar mee wordt gezwaaid in de lucht, in de holster wordt gestoken, of een ander zwaard raakt. De categorie ‘deur’ bestaat zelfs louter uit sterk variërende sci-fi effecten voor deuren in futuristische games, dit om de brede toepasbaarheid van de AI-aanpak te testen. Mogelijk vraagt u ook af waarom het glas de laagste tonen van de dataset zijn: deze twee audiofiles representeren minuscule glasscherven die worden verschoven, niet bepaald hetzelfde geluid dat u hoort wanneer u een wijnfles in de glasbak kegelt.
Trainen van een AI
In plaats van een dataset met audiobestanden hebben we nu een dataset die is omgevormd tot afbeeldingen. We gaan dus hetzelfde type neuraal netwerk gebruiken dat kan worden gebruikt om honden van katten te onderscheiden, zelfrijdende auto’s objecten laat detecteren, gezichten kan herkennen, of visuele bugs kan detecteren in games. Dit type neuraal netwerk noemt een Convolutional Neural Network, of kortweg CNN. CNN’s zijn vaak de go-to AI-oplossing voor alles waarbij visuele input moet worden verwerkt. Indien u interesse heeft in hoe dit precies werkt, bekijk dan zeker eens de workshop ‘Computervisie in Unity’.
We trainen de AI op zes verschillende van de vijftien categorieën met geluidseffecten als eerste experiment. Dit duurt slechts enkele seconden, en de gerapporteerde accuraatheid is 96%. Vervolgens gebruiken we een confusion matrix om te meten in hoeverre de AI in staat is om audio per categorie te onderscheiden.[DR4]
Op de verticale as van de confusion matrix ziet u de effectieve labels. De horizontale as toont wat de voorspelling was van de AI. In de eerste kolom kunt u aflezen dat 76 van de voorspellingen ‘polystyrene’ correct waren, en dat éénmaal het geluid van glas foutief werd verward met polystyreen, wat al bij al begrijpelijk is. De AI had het meeste moeite met de voorspelling ‘glass’, waarbij hij tweemaal het geluid van een zwaard en driemaal dat van polystyreen foutief labelde als glas. Los hiervan zijn de resultaten best indrukwekkend, de foutmarge is hier zeer laag (op honderden voorspellingen in het totaal slechts 8 fouten) en we kunnen bijgevolg vrij zeker zijn dat de AI in staat is om geluidseffecten correct in te delen.
Vervolgens kan deze ook deze kennis worden geëxtrapoleerd naar nieuwe sound effects die tot dezelfde categorie behoorden. Bijvoorbeeld wanneer we de AI trainen op verschillende samples van gebroken of brekend glas, dan hoeft deze niet volledig opnieuw te worden getraind om een nieuwe variatie van brekend glas te herkennen.
De meerwaarde hiervan is dat factoren zoals compressie of andere lichte vervormingen van de audio geen invloed hebben op de detectie mogelijkheden van de AI. Ook procedureel gegenereerde audiobestanden kunnen op die manier nog steeds aan hun juiste categorie worden gekoppeld.
Vervolgstappen
Het is duidelijk dat een CNN gebruiken voor audio dé juiste aanpak is, en dat het zelfs met sterk uiteenlopende audio goed werkt. De logische volgende stap is om met een veel grotere dataset te werken.
De database die we hiervoor gebruiken is AudioSet, een gigantische audio collectie van Google die uit 527 categorieën aan verschillende geluiden bestaat van 10-seconde audiofragmenten uit meer dan 2 miljoen video’s samen, wat neerkomt op 5800 uur aan audio.[DR5]
We duiken nog even dieper in op de ontologie van de dataset:[DR6]
Dit is slechts een beknopt overzicht, bijvoorbeeld voor de categorie paard heb je nog 4 verschillende categorieën, bestaande uit blazen, snuiven, hinniken en galopperen. We kunnen dus op een zeer gedetailleerd niveau audio van allerlei bronnen gaan annoteren.
Uiteraard, deze dataset is niet noodzakelijk representatief voor elk type game, aangezien geluidseffecten voor de meeste games uniek zijn en bovendien eigen zijn aan het genre dat wordt gespeeld. Een FPS shooter gaat niet dezelfde sound effects hebben als een cartoony platform game. We hebben reeds aangetoond dat het perfect mogelijk is om op kleinere schaal een AI voor uw eigen game te trainen.
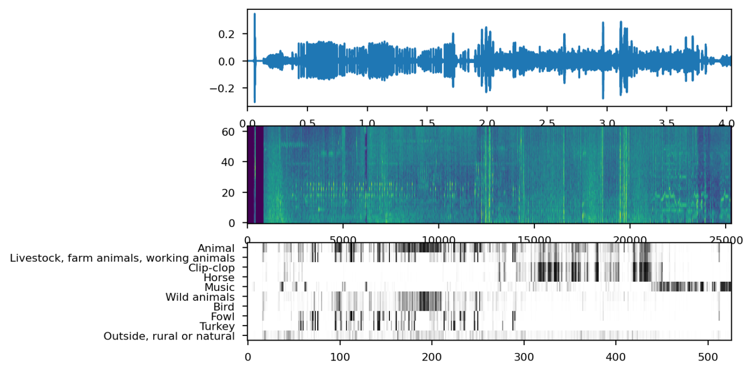
Naast het annoteren van individuele audiofragmenten zijn we een stap verder gegaan met onze nieuwe AI. Met name voor langere of continue geluidsfragmenten is het juist belangrijk om individuele events te detecteren. We gaan dus verschillende en mogelijks zelfs overlappende audioclasses gaan distilleren door timestamps bij te houden van gedetecteerde audiofragmenten. Op deze manier kunnen we een overzicht genereren van de volledige audiofile met de 5 meest voorkomende categorieën.
Om te verifiëren hoe goed deze dataset werkt hebben we deze op verschillende type games losgelaten met variërende genres. Het resultaat voor elk type game ziet u hier:[DR7]
Zoals u kunt zien is het voor elk spel in één oogopslag duidelijk wat u kunt verwachten qua audio.
Indien u op zoek bent naar een bepaald audio event in een lange opname dan hoeft u deze ook niet meer van A-Z te bekijken om zeker te zijn dat u geen enkel moment per ongeluk heeft overgeslagen.
Aan de hand van deze informatie is het detecteren van ontbrekende, foutieve
of vertraagde audio-effecten een koud kunstje. Ook is het perfect mogelijk om te gaan interpreteren of de juiste audio wordt afgespeeld. Voor bepaalde acties kunt u een trigger gaan instellen met een bepaald label. Wordt de verwachte audio niet binnen de x aantal milliseconden afgespeeld, dan kan het geen kwaad om hier eens een melding van te maken.
Slot
Het doel van ons onderzoek was om te onderzoeken in welke mate het mogelijk is om geluidseffecten te gaan detecteren. Bij deze kunnen we bevestigen dat we weldegelijk in staat zijn om met hoge accuraatheid geluidseffecten in games te gaan detecteren met AI, sterker nog, we kunnen op een zeer efficiënte manier mooie overzichten gaan genereren voor lange opnames.
We kunnen concluderen dat het inzetten van AI om audio events te detecteren zeer succesvol is. Met de juiste data voor handen is het vrij eenvoudig om een AI te trainen, dit zelfs zonder speciale systeemvereisten. Voor het oplossen van specifieke problemen met audio kan dit helpen tijdens het development proces, om foutieve, ontbrekende en vertraagde geluidseffecten te detecteren.
Ook is deze technologie mogelijk interessant voor andere use cases, waarbij er automatisch uit niet-geannoteerde videofragmenten een compilatie wordt gemaakt. Wanneer je al de explosies uit een shietspel wilt samenvatten en herbekijken uit een gameplay video van één uur is dit de go-to oplossing.
Een mogelijk interessant vervolgonderzoek om uitdagingen met audio of specifieke meer technische aspecten van audio te onderscheiden met een AI-oplossing maakt een grote kans om waardevolle resultaten op te leveren.
Code en resultaten
We hebben twee notebooks die u op weg kunnen helpen om zelf aan de slag te gaan met de besproken technologie. U kunt de resultaten terugvinden in deze notebooks.
Trainen van een AI op uw eigen audio dataset: Google Colab
Gebruiken van een pre-trained AI op AudioSet om opnames samen te vatten: Google Colab