Overview: Reinforcement learning in games
In deze blogpost geven we een korte inleiding tot Reinforcement Learning (RL) en bekijken we een aantal toepassingen binnen de game wereld. Het doel is om jullie ideeën te prikkelen, en ook om aan te tonen dat je geen AI expert moet zijn om met deze technologieën aan de slag te gaan. We kijken uit naar vragen of ideeën die uit deze blogpost volgen en nemen alle input graag mee ter voorbereiding van de geplande workshops.
Reinforcement learning
RL is een AI-techniek die gebaseerd is op concepten uit de gedragspsychologie. Net zoals we gewenst gedrag kunnen leren aan kinderen d.m.v. straf en beloning, kunnen we dit ook doen voor virtuele entiteiten, ook wel agents genoemd in het jargon.
Het grote voordeel van RL is dat we niet noodzakelijk veel data nodig hebben om een model te trainen, een vereiste die de meeste andere Machine Learning technieken wel hebben. Wat hebben we dan wel nodig? Een leeromgeving, typisch environment genoemd, en tijd om de agent hierbinnen op ontdekking te laten gaan. Een typische RL-leerproces kunnen we schematisch als volgt voorstellen:
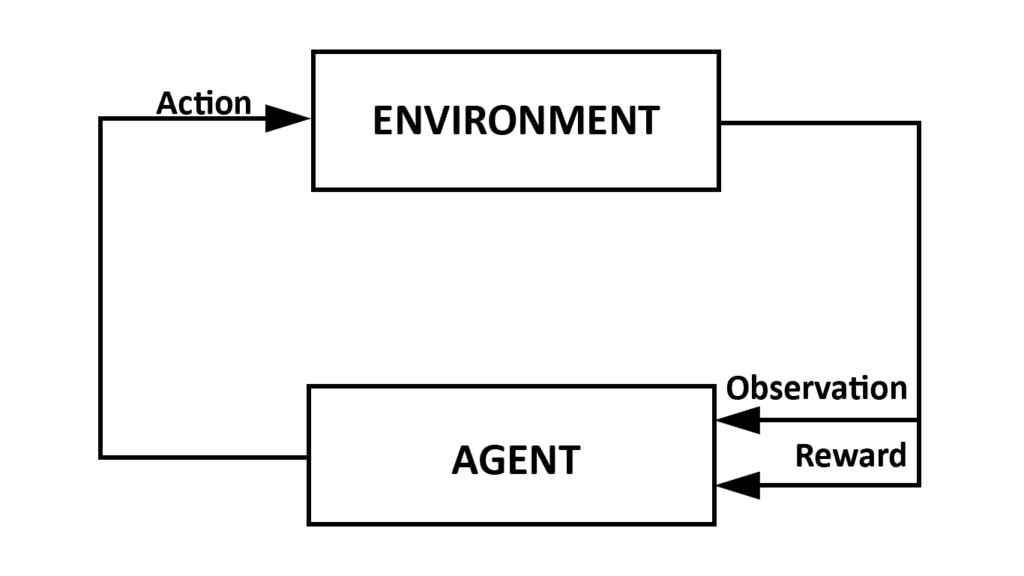
Het leerproces waarin de agent een nieuw gedrag leert wordt typisch trainen genoemd en verloopt iteratief. In de eerste stap observeert de agent telkens de staat van de omgeving. De observatie vertelt de agent meer over zichzelf en de omgeving. Dit kan gaan van zijn locatie, afstand tot een bepaald object, tijd… Deze informatie hoeft niet numeriek te zijn: ook pixeldata kan gebruikt worden. Op basis van die observatie kiest de agent dan een actie en voert deze uit. Hij observeert de nieuwe omgeving, en ontvangt ook een beloning (reward). Het gedrag van een agent, ook wel policy genaamd, omvat eigenlijk een mapping van observaties naar acties.
De value function en Artificiële Neurale Netwerken
Welke actie een agent neemt hangt af van het waardeoordeel die volgde op elke actie en is gebaseerd op zijn observatie van de leeromgeving. Dit waardeoordeel wordt gegeven door een value function, en weerspiegelt de verwachtte beloning die de agent zal ontvangen indien hij deze actie neemt. Deze voorspelling wordt bijgesteld doorheen het leerproces op basis van de opgedane ervaringen. Het vinden van de juiste policy is eigenlijk hetzelfde als het vinden van een value function die toekomstige beloningen maximaliseert. In de meest recente methodes wordt de value function geïmplementeerd d.m.v. een Artificieel Neuraal Netwerk (ANN), een term die u waarschijnlijk al vaak heeft horen vallen in gesprekken rond AI.
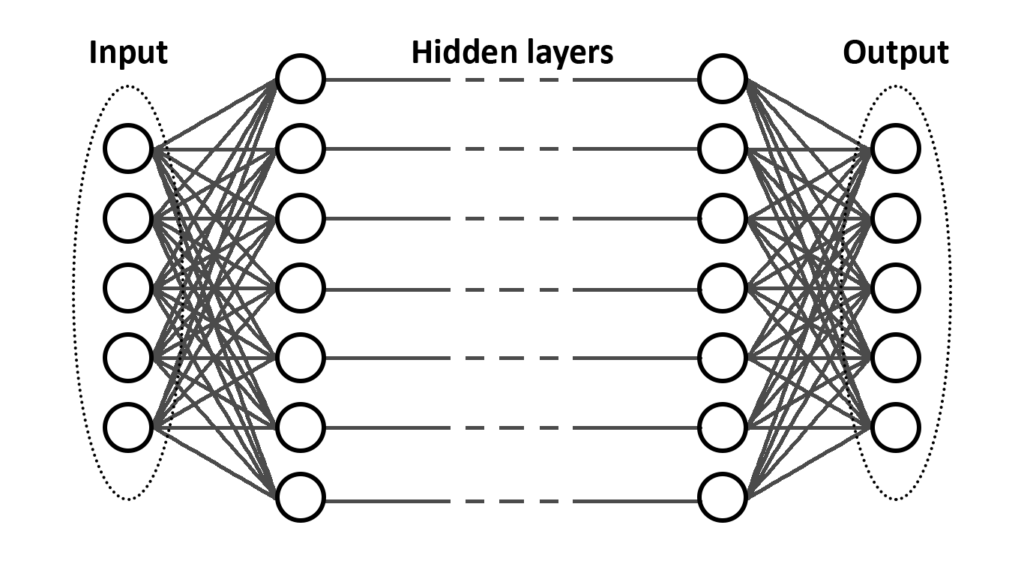
Een ANN bestaat uit verschillende lagen van nodes die onderling met elkaar verbonden zijn. De eerste laag is de input van het netwerk, en komt overeen met de observatie van de agent. De laatste laag komt overeen met de acties die de agent kan nemen. Alle lagen ertussen zijn bewerkingen, die gaan bepalen op basis van de observatie welke actie optimaal is. Het trainen van een agent komt neer op het finetunen van de parameters van het Neurale Netwerk. Dit finetunen gebeurt door de voorspelde beloning te vergelijken met de verkregen beloning in het leerproces.
Reward function
De beloningen bepalen rechtstreeks het gedrag dat de agent zichzelf gaat aanleren. Het vinden van de juiste beloningsmechanismen of reward functions, wordt uitdagender naarmate de complexiteit van de leeromgeving stijgt. In het simpele spel Pong bijvoorbeeld is het eenvoudig om een reward functie te bedenken: -1 wanneer de agent de bal mist, en +1 wanneer de agent een punt scoort. Van zodra de complexiteit stijgt is het duidelijk dat we met een moeilijkere denkoefening zitten. Wat het nog moeilijker maakt is dat in games de beloningen vaak pas komen na het nemen van een hele reeks acties die aan elkaar vasthangen
Met behulp van imitation learning kunnen we het leerproces van de agent aanzienlijk versnellen, we maken het bedenken van reward functies makkelijker. Door middel van opnames van gewenst voorbeeldgedrag kunnen we een beloning geven aan agents op basis van hoe hun gedrag afwijkt van deze opnames. Deze opnames dienen wel manueel gemaakt te worden.
Toepassingen in games
De toepassingen van RL in games lopen uiteen en in theorie zijn de mogelijkheden eindeloos. Vanuit de literatuur zien we al langer een interesse om RL toe te passen in games, omdat games scenario’s aanbieden die eenvoudiger zijn dan de echte wereld, maar wel uitdagend genoeg om te bewijzen dat de AI algoritmes werken.
De state-of-the-art rond RL wordt momenteel ontwikkeld door Google DeepMind. Dit team ontwikkelt een agent die beter Starcraft2 kan spelen dan alle pro’s. Hun agent, die de naam AlphaStar kreeg, was in oktober 2019 al beter dan 99.8% van de menselijke Starcraft2 gamers. Het doel van het Google Deepmind team is niet enkel om een superbot te maken, maar ook (en vooral) om het domein van RL verder te verkennen en uit te breiden. Het is deze kennis die wij opnieuw kunnen gebruiken voor andere toepassingen.
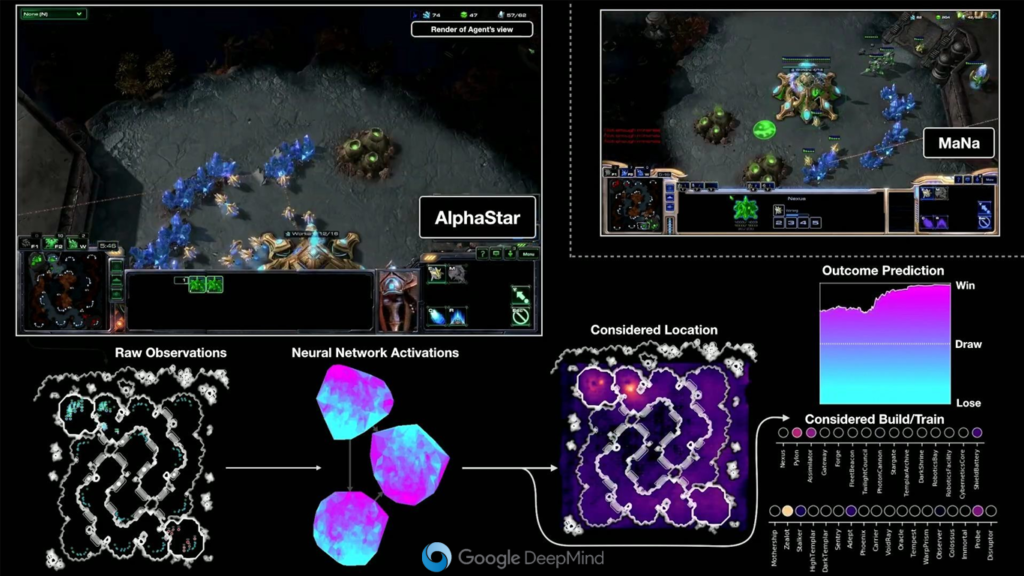
RL onderzoek beperkt zich niet tot het spelen van real-time strategy games. Ook voor first-person-shooters, tekst-adventures, team-sports, race- arcade- en open-world games werden al agents getraind die geslaagde speelsessies voltooiden. Deze successen duiden op de mogelijkheden om RL te gebruiken binnen de context van games.
Deze agents kunnen ingezet worden op verschillende vlakken. We geven enkele voorbeelden. Een agent die menselijk spelgedrag kan benaderen zou ingezet kunnen worden om gameplay balanceringstesten uit te voeren. Agents kunnen voor ons ook interessante inzichten verschaffen en data verzamelen tijdens ons productieproces wanneer we nieuwe content maken. Denk maar aan een agent die een nieuwe map of level verkent, een agent die tegen een nieuwe vijand vecht, een agent die een nieuw wapen uitprobeert of een puzzel probeert op te lossen …
Aan de slag!
Hoe start je als game dev nu met het ontwikkelen van een nuttige RL-agent? Eerst en vooral start je denkoefening met de vraag waar exact u deze agent voor zou willen inzetten. Wat zullen de agent zijn taken zijn? Welke observatie heeft hij hiervoor nodig en welke acties kan hij ondernemen? Zorg dat de antwoorden op die vragen eenvoudig en afgelijnd zijn.
Beslissingsniveaus
We maken een onderscheid tussen 3 niveaus waarop agents, net zoals spelers, beslissingen nemen: strategisch, tactisch en instant. Op het laagste niveau zien we de beslissingen over welke input we gaan geven in de game. Dit gaat puur over het gebruik van controllers. Op een niveau hoger gaan de beslissingen eerder over kleine taken: een deur openen, een tactische navigatie, een puzzel oplossen. Nog een niveau hoger gaan de beslissingen over grotere strategieën: resource managent, totale plan van aanpak om een game te winnen of leger composities. Om samen te vatten: een strategische beslissing bestaat uit meerdere tactische beslissingen, die op hun beurt bestaan uit instant beslissingen.
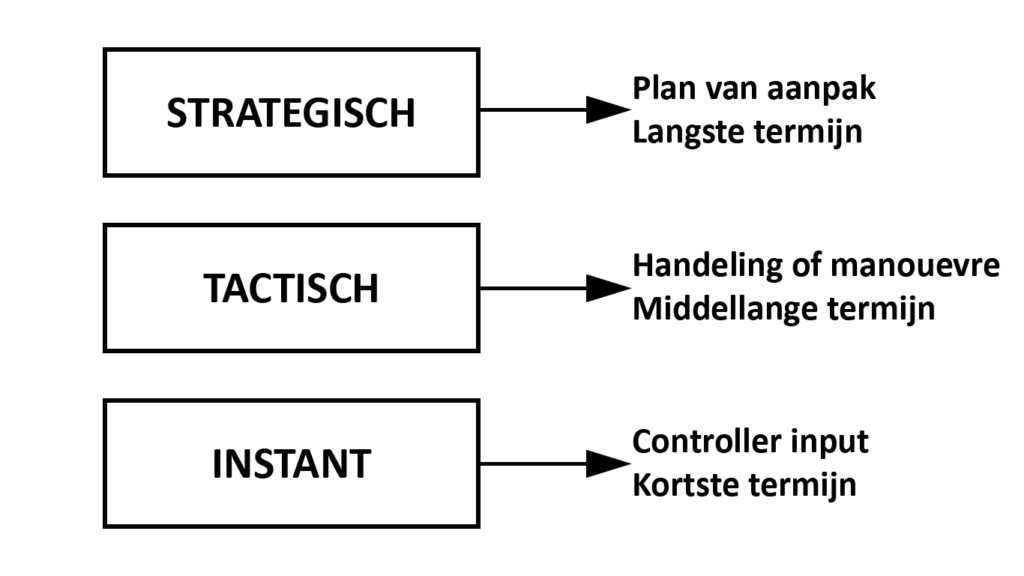
Het is eenvoudiger om een agent te trainen die beslissingen neemt op 1 bepaald niveau dan een agent die op alle niveaus tegelijk handelt. Het is dus goed om na te denken welke taken geleerd moeten worden door de agent, en welke door een ander systeem (pathfinding, animatie, tree-search…) kunnen worden overgenomen. Dit heeft ook invloed op de observatie. Een agent die redeneert over de logische stappen om een deur te openen, heeft minder nood aan observaties die te maken hebben met vijanden of score. (Tenzij deze een trigger vormen om de deur te openen natuurlijk.)
Implementatie
Gelukkig is het niet nodig om van nul af aan te beginnen aan een implementatie van alle RL-algoritmes. Er zijn tal van gratis (open-source) bibliotheken ter beschikking. De meest bekende zijn Tensorflow, Keras, Pytorch en OpenAI. Ze beschikken over een Python front-end die het gemakkelijk maakt om een eigen applicatie te linken en neurale netwerken samen te stellen. Indien je werkt in Unity3D kan je opteren om gebruik maken van Unity ML-agents, een open-source plug-in die gebruik maakt van Tensorflow en de beste RL-algoritmes klaar voor implementatie aanbiedt.
Het trainen van agents vereist natuurlijk een simulatieomgeving waarbinnen ze de kans krijgen om te leren. Om het trainen van agents optimaal te laten verlopen, zijn bepaalde aspecten van deze omgeving van belang: snelheid, stabiliteit, determinisme en observaties. Snelheid is triviaal, hoe sneller uw simulatie kan lopen, hoe sneller agents kunnen trainen. Stabiliteit en determinisme hangen deels samen. Bij versnelde simulaties waarin de agents trainen, is het belangrijk dat zaken zoals physics even correct blijven werken. Snelheid kent zijn limiet waar de simulatie fouten begint te vertonen door precisieverlies, en dus instabiel wordt. Als laatste dient een agent ook eenvoudig een observatie te kunnen doen van de omgeving. Dit kan zoals gezegd via pixel data, maar vaak is het eenvoudiger om zelf te kiezen wat de agent observeert. Door middel van ray-casts, locaties en info over de agent is het eenvoudiger om controle te houden over waar de agent op let.
Nuttige en interessante links
Unity ml-agents: https://github.com/Unity-Technologies/ml-agents
RL penguins in Unity ml-agents: https://www.immersivelimit.com/tutorials/reinforcement-learning-penguins-part-1-unity-ml-agents
Het AlphaStar project van Google Deepmind: https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
Getting started with RL and Tensorflow: https://www.tensorflow.org/agents/tutorials/0_intro_rl
Spinning up in deep RL with OpenAI: https://openai.com/blog/spinning-up-in-deep-rl/
Getting started with RL and PyTorch: https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html