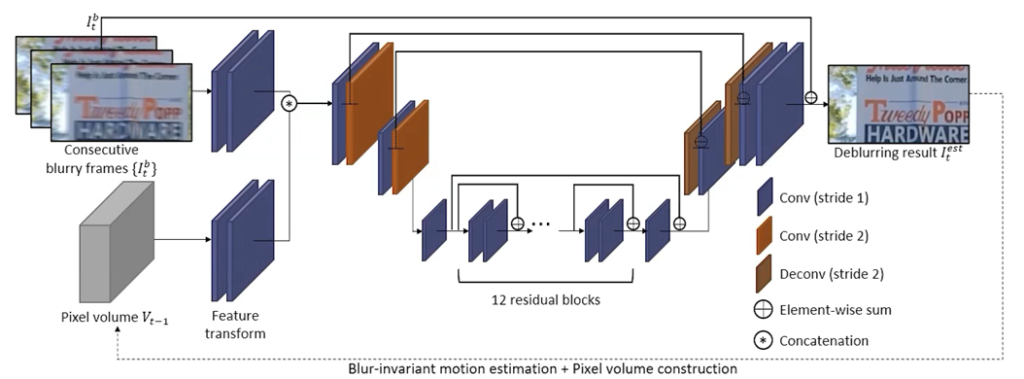
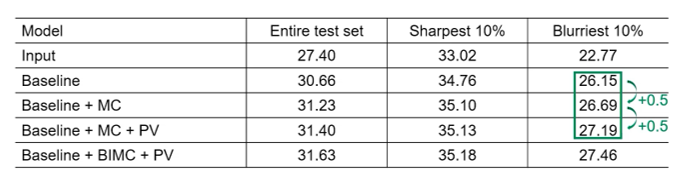
Aangezien we tijdens de TETRA tot nu toe nog niet zo veel focus gelegd hebben op het VFX aspect van AI in productie, kozen we ervoor om ter voorbereiding van de brainstorm in januari al even kort de viability te testen van een use case rond Video Deblurring. In teken hiervan testten we de bestaande pre-trained models zelf uit, en schreven we deze blogpost. Later in deze blogpost volgen de resultaten van de onze eigen tests, maar eerst leggen we uit hoe deze techniek werkt.
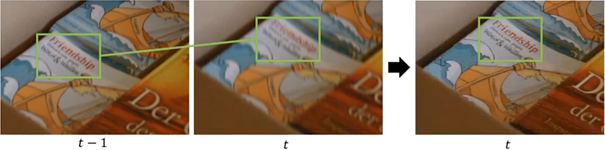
Het doel van Video Deblurring is het verwijderen van motion blur veroorzaakt door cameratrillingen en objectbeweging.